
SEO | 8 – SEO ONSITE, OTTIMIZZAZIONE CODICE HTML, ROBOT.TXT E HTACCESS
8b, IL CANONICAL. COME SPIEGARE A GOOGLE QUAL È LA PAGINA GIUSTA DA PRENDERE IN CONSIDERAZIONE TRA DUE SIMILI O UGUALI
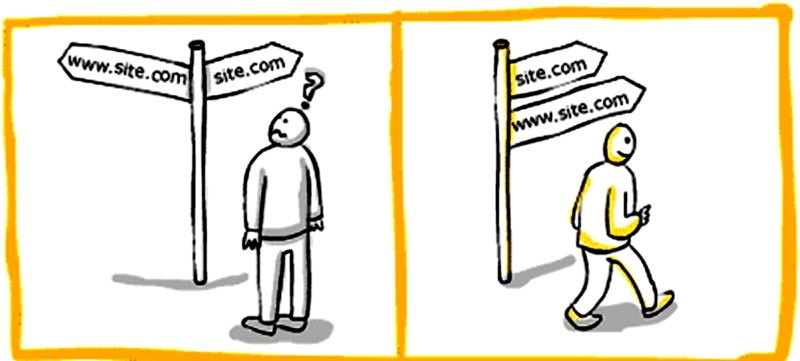
I canonical URL sono qualcosa di molto importante dal punto di vista SEO e sono utili anche per indicizzare meglio i propri contenuti originali senza che vengano “rubati”.
Se c’è una pagina accessibile da più URL o da pagine diverse con contenuti simili Google li vede come versioni duplicate della stessa pagina. Google sceglierà un URL come versione canonica e lo sottoporrà a scansione, e tutti gli altri URL saranno considerati URL duplicati e scansionati meno spesso.
Bisogna comunicare a Google quale URL è canonico sennò sceglierà da solo quale sarà la pagina da indicizzare!

-> Guida al Canonical di Valentino Mea
Il rel=canonical è un elemento HTML che serve a comunicare ai motori di ricerca, in presenza di due URL con contenuto identico o simile, qual è la pagina canonica, ovvero la pagina da considerarsi come “originale”.
In pratica, il rel=canonical si utilizza per evitare le duplicazioni di contenuti, che in ambito SEO possono penalizzare il ranking di un sito.
Immaginate il rel canonical come una specie di “etichetta” applicata a una pagina, che risponde alla domanda “a quale URL appartiene il contenuto originariamente?”. La risposta potrebbe essere:
->a questa stessa pagina (quindi la pagina è canonica);
-> a un’altra pagina (che invece è la pagina canonica, indicando qual è).
Come implementare il rel=canonical
Aggiungi nel codice della per tutte le pagine (in HEAD) duplicate un tag che indirizza gli spider dei motori di ricerca alla pagina canonica. Puoi utilizzare un tag nell’intestazione HTTP della pagina per segnalare quando una pagina è un duplicato di un’altra.
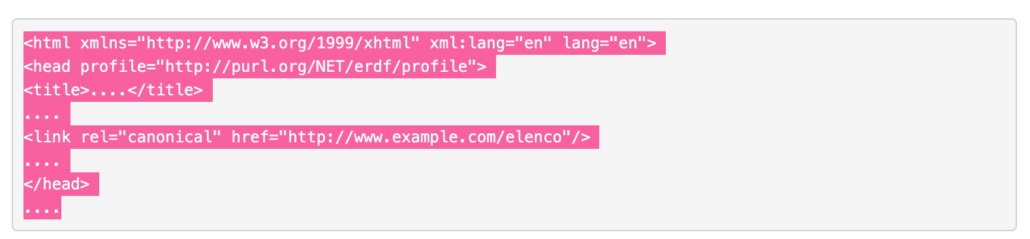
Lo stesso canonical dovrà essere utilizzato per tutte quelle pagine che non sono altro che duplicati di questa pagina:
- www.example.com/elenco avrà come canonical http://www.example.com/elenco
- www.example.com/elenco/nome avrà come canonical http://www.example.com/elenco
- www.example.com/elenco/cognome avrà come canonical http://www.example.com/elenco
- In generale:
Scegliere una delle due pagine e rendila la versione canonica inserendo nelle pagine NON canoniche la stringa
Fare in modo che la scelta ricada sulla pagina più importante
Esistono diversi motivi per cui conviene scegliere espressamente una pagina canonica in un insieme di pagine duplicate o simili:
- Specificare l’URL da mostrare nei risultati di ricerca. Gli utenti che arrivano dai motori di ricerca dovrebbero atterrare qui https://sitogomme.it/205-55-15/ e non qui https://sitogomme.it/205-55-15/?ordinamento=prezzo. Una pagina di listing potrebbe generare decine, centinaia o anche migliaia di varianti URL con gli stessi prodotti. Questa situazione per Googlebot è un inferno se non viene gestita correttamente con canonical e “Gestione parametri” in Google Search Console.
- Consolidare i segnali associati ai link per pagine simili o duplicate. Consente ai motori di ricerca di consolidare le informazioni in loro possesso in merito ai singoli URL (ad esempio, link che rimandano a tali URL) in un unico URL preferito. Ciò significa che i link presenti in altri siti che rimandano a http://sitogomme.it/205-55-15/?ordinamento=prezzo vengono consolidati con i link che rimandano a https://sitogomme.it/205-55-15/. I backlink già sono rari, se poi vengono diluiti in altre pagine senza valore si farebbe un danno SEO molto grave.
- Semplificare il monitoraggio delle metriche relative a un singolo URL. La presenza di URL multipli (normali e parametrizzati) nei report di Google Analytics o Google Search Console rende più complicato ricevere metriche consolidate per un contenuto specifico.
- Gestire i contenuti duplicati distribuiti ad altri siti web. Se distribuisci in syndication i contenuti per pubblicarli (o farli pubblicare) su altri domini, ti conviene consolidare il ranking delle pagine con il tuo URL preferito per evitare che le pagine clone vengano indicizzate e posizionate prima delle tue.
- Aiutare Googlebot a non scansionare pagine duplicate. Per ottimizzare la scansione del sito ed il crawl budget, è preferibile che Googlebot sottoponga a scansione pagine nuove (o aggiornate), anziché le versioni filtrate e duplicate di una stessa pagina. Ricordati che il tempo che Googlebot assegna alla scansione del tuo sito non è infinita.
-> https://www.evemilano.com/rel-canonical/
In caso di contenuti duplicati meglio CANONICAL o REDIRECT?
Si utilizzano i reindirizzamenti 301 per indicare a Google che un URL reindirizzato è una versione migliore dell’URL prestabilito. Si adotta questo metodo solo per rendere obsoleta una pagina duplicata. Un redirect è più veloce ed efficace del tag rel canonical, ma in certi casi non sarebbe corretto rindirizzare l’utente!
Supponiamo che sia possibile accedere alla pagina in diversi modi:
https :// sitogomme.it/home
https :// home.sitogomme.it
https :// www.sitogomme.itSi sceglie uno di questi URL come URL canonico e si utilizzano i reindirizzamenti 301 per inviare il traffico dagli altri URL all’URL preferito. Un reindirizzamento 301 lato server sul file htaccess ad esempio è il modo migliore per assicurarsi che utenti e motori di ricerca siano indirizzati alla pagina corretta. Il codice di stato 301 indica che una pagina è stata spostata definitivamente in una nuova posizione come abbiamo già appurato.
![]() Approfondisci: https://www.roberto-serra.com/canonical-url-cose-e-perche-non-puoi-farne-a-meno-lato-seo/
Approfondisci: https://www.roberto-serra.com/canonical-url-cose-e-perche-non-puoi-farne-a-meno-lato-seo/
8c. MAPPA DEL SITO E ARCHITETTURA DELLE INFORMAZIONI
Un altro elemento importante riguarda la struttura del sito o mappa del sito stesso ottimale se gerarchica perché facilmente scansionabile dai robot.
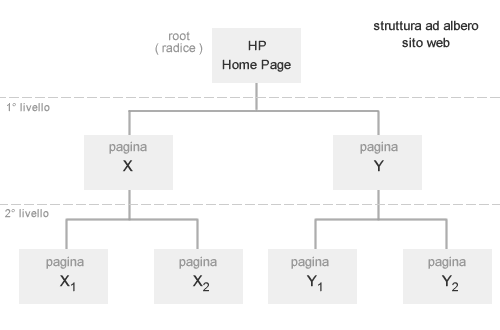
Un esempio di struttura “ad albero” comprensibile per i motori di ricerca.
Bisogna anche verificare ed eventualmente sistemare la presenza di link non funzionanti all’interno del nostro sito, poiché un numero eccessivo di “broken link” può far supporre ai motori che il sito sia abbandonato.
Per approfondire leggi anche come ottimizzare la meta tag description e come ottimizzare il tag title. Puoi anche leggere questa guida all’ottimizzazione del codice HTML di STUDIO SAMO.
LA SITEMAP
Per creare una mappa in XML, RSS, TESTO:
https://support.google.com/webmasters/answer/183668?hl=it
es. per un singolo URL
xml version="1.0" encoding="UTF-8"?>
xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
http://www.example.com/foo.html
2018-06-04
Come caricarla sul sito e renderla utile per il SEO
-> Utilizzare Google Search Console -> Mappa del Sito
-> Caricarla con un plugin del proprio CMS (es. per wordpress YoastSeo)
Esistono per fortuna dei generatori automatici di sitemap in XML come: https://www.xml-sitemaps.com/
Architettura delle informazioni
A proposito di sitemap, fondamentale è che il sito web risponda ad una struttura ed una architettura delle informazioni ordinata!
Una buona struttura facilita agli utenti navigare tra le pagine del tuo sito e ai motori di ricerca scansionarne i contenuti e capire di cosa tratta.
Pensa a come le pagine del tuo sito web si relazionano tra loro, in particolare come si diramano dalla tua home page e si raggruppano in directory più complesse.
Pianificare una struttura del sito include considerare:
- Strutture degli URL
- Menu di navigazione
- Categorizzazione
- Breadcrumbs
- Internal linking
In questo caso sitogruppostrutturemediche.it/nome-struttura/servizio-dellastruttura
+ bread crumb
+ h1

I backlink sono un fattore di ranking chiave. Per massimizzare i vantaggi della tua strategia di link building, devi assicurarti di distribuire correttamente la link authority in tutto il tuo sito (questa pagina del sito fabiozanchetta.it sul SEO non è ben ottimizzata SEO perché non rìsponde all’ordinamento per cluster)
Per guadagnare backlink di alta qualità, devi avere pagine diverse che rispondano a domande diverse. In questo modo, avrai diverse pagine sul tuo dominio vantaggiose per gli utenti. E potrai anche acquisire backlink più pertinenti e di qualità.
in astratto:
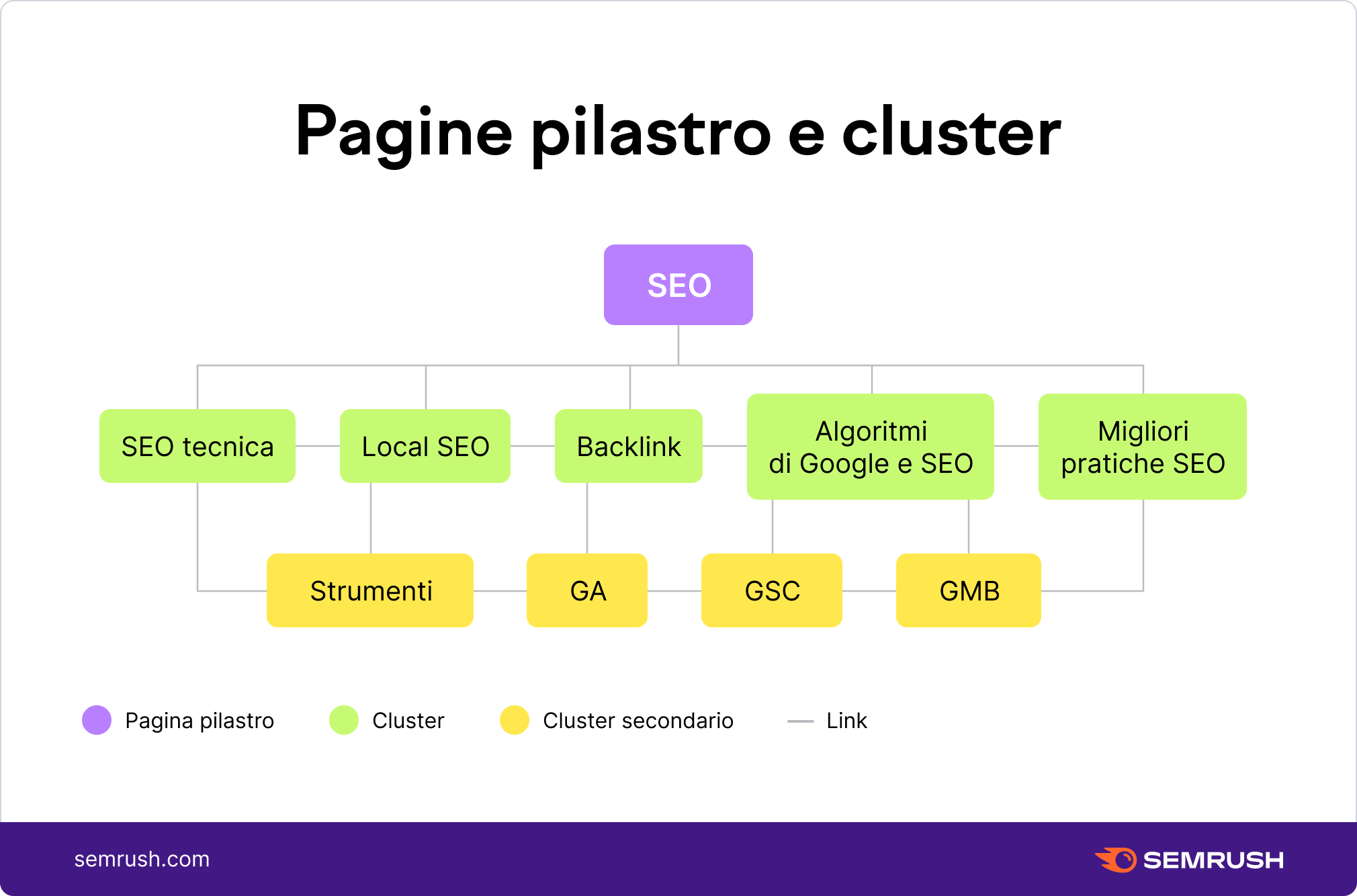
Leggi: https://it.semrush.com/blog/struttura-di-un-sito-per-la-seo/
8D. LE RELAZIONI: NOFOLLOW – NOINDEX
L’indicizzazione delle pagine web (e anche la deindicizzazione delle pagine web) dipende dai meta tag robots, che comunicano ai motori di ricerca varie informazioni (ad esempio che keywords scelte, i titoli delle pagine, la natura dei link) nonché la nostra scelta di indicizzare o meno una pagina, di inserirla negli archivi dei motori di ricerca e di dare o meno importanza ai link contenuti sulla pagina.
Noindex/index
L’attributo rel=”noindex” comunica a Google la nostra intenzione di non voler indicizzare la pagina, anche se non è detto che Google segua le nostre direttive.
In questo modo la pagina non esisterà più per i motori di ricerca, ma gli utenti continueranno a visualizzarla: questo farà sì che non si accumulino sul nostro sito delle spam engine, ma al tempo stesso eviterà che i backlink esterni e quelli interni rimandino ad una pagina 404.
Nofollow/follow
L’attributo rel=”nofollow” agisce in maniera diversa rispetto al noindex che, come abbiamo visto, serve a deindicizzare una pagina.
Il nofollow indica a Google di non seguire i link contenuti in una pagina specifica, né di dar loro peso in termini di posizionamento, attribuendo valore al sito che riceve i link.
Questi meta tag, inseriti nella head della pagina HTML, è dato dal seguente codice:
meta name=”robots” content=”nofollow“
Il valore per l’attributo content definisce l’istruzione allo spider relativo alla pagina:
-
- index – si richiede di indicizzare la pagina (di inserirla cioè nell’archivio del motore di ricerca);
-
- noindex – si richiede di non includere la pagina negli archivi del motore di ricerca;
-
- follow – si richiede che tutti i link presenti nella pagina vengano seguiti; questo consente anche il passaggio di valore da una pagina all’altra, come avremo modo di vedere in modo molto ampio;
-
- nofollow – si richiede di non seguire i link che da quella pagina puntano verso altre pagine.
Questo metatag si distingue dal file robots.txt perché si riferisce alla singola pagina in cui è presente, e non al sito nel suo complesso e quindi il crawler agirà solo su quella pagina.
I valori relativi all’indicizzazione (index/noindex) e quelli relativi ai link (follow/nofollow) possono essere combinati tra loro.
Abbiamo così quattro alternative:
I valori relativi all’indicizzazione (index/noindex) e quelli relativi ai link (follow/nofollow) vengono combinati tra loro.
Abbiamo così quattro alternative:
meta name=”robots” content=”index, follow“
Si richiede di indicizzare la pagine e seguire tutti i link.
meta name=”robots” content=”index, nofollow“
Si richiede di indicizzare la pagina ma non seguire i link.
meta name=”robots” content=”noindex, follow“
Si richiede di non indicizzare la pagina, ma di seguire i link che da quella pagina portano ad altre pagine.
meta name=”robots” content=”noindex, nofollow“
Si richiede allo spider di non indicizzare e non seguire i link di quella pagina.
Quando si cercando di produrre backlink con il link building/earning è fondamentale verificare se ci sono dei nofollow.
Il nofollow è un attributo che – si può dire – impedisce al link juice di fluire ad un sito web. Questa è una cosa molto comune ad esempio nei link presenti nella sezione commenti di un blog.
Per scoprire se i link che puntano al tuo sito passano il succo del collegamento, devi verificare se i link hanno l’attributo nofollow al loro interno. Se ce l’hanno, allora il link che hai lavorato così duramente per ottenere non sta facendo molto per te, in quanto l’attributo nofollow dice fondamentalmente a Google di ignorare la tua pagina web.

Nell’immagine qui sopra vediamo che è possibile inserire l’istruzione nofollow per singoli link. Questo può essere utile se vogliamo ad esempio permettere allo spider di seguire i link della pagina, tranne alcuni specifici.
Per farlo possiamo utilizzare l’attributo rel=”nofollow” del tag relativo al singolo link.
Es.:
a href=”http://www.altrosito.it” rel=”nofollow”>Altrosito
Perché usare noindex se abbiamo il disallow su Robots.txt? Il file robots.txt impedisce del tutto l’accesso dello spider a determinate cartelle e file tramite l’istruzione Disallow, mentre il meta tag robots permette in ogni caso l’accesso alla pagina, istruendo lo spider sulla fase successiva: se indicizzare o meno la pagina, se deve seguire o meno i link; si tratta di un metodo che permette di istruire in modo ancora più preciso e specifico lo spider.
8e, ROBOTS.TXT
Il robots.txt è un file di testo che permette al Webmaster di fornire una serie di istruzioni ai motori di ricerca riguardo ciò che possono e ciò che non possono fare all’interno del nostro sito.
Queste istruzioni seguono il cosiddetto Robots Exclusion Protocol (REP), le cui specifiche sono disponibili sul sito www.robotstxt.org .
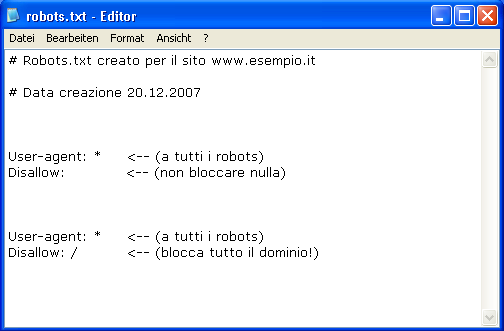
Il file robots si presenta nel formato txt e codifica UTF-8 e contiene alcune semplici istruzioni.
Un’istruzione base allo spider è dato da due righe:
– User-agent
Questo elemento specifica a quale spider si applica l’istruzione.
User-agent: *
con * (asterisco) si indica che l’istruzione riguarda tutti gli spider .
Se vogliamo specificare l’istruzione ad uno spider preciso, dovremmo scrivere il nome dello spider. Nel caso di Google lo spider principale è Googlebot.
Scriveremo quindi:
User-agent: Googlebot
L’elenco dei nomi degli spider è disponibile su robotstxt.org.
– Disallow
La riga definita dal valore Disallow dice allo spider quale cartella o file del sito non deve essere visto e indicizzato; serve di fatto ad impedirne l’accesso.
Ipotizziamo di avere una cartella /admin contenente aspetti relativi all’area amministrativa del sito e di volere impedire che venga visto dallo spider. Scriveremo:
User-agent: *
Disallow: /admin/
Possiamo invece impedire, ad esempio, l’indicizzazione su Google Immagini di una cartella contenente le immagini: ad esempio la cartella /immagini del nostro sito (www.miosito.it/immagini).
Scriviamo:
User-agent: Googlebot-Image
Disallow: /immagini/
Possiamo dare istruzioni relative ad un singolo file. In questo caso scriveremo, ad esempio:
User-Agent: *
Disallow: /immagini/foto1.jpg
Allow
Possiamo anche utilizzare il termine Allow per permettere la visione e l’indicizzazione di alcune pagine o cartelle.
Può essere utile se abbiamo impedito l’accesso ad una cartella (ad esempio la cartella /immagini) ma vogliamo permettere l’indicizzazione di un file al suo interno (ad esempio il file /immagini/foto1.jpg).
Scriveremo:
User-Agent: Googlebot-Image
Disallow: /immagini/
Allow: /immagini/foto1.jpg
In questo caso impediamo la scansione e l’indicizzazione di tutti i file contenuti dentro la cartella /immagini tranne che per il file foto1.jpg .
Carattere * e $
Il carattere * , rispettato dagli spider di Google e Bing, è utilizzato non solo a livello dell’User-agent (qui sta a significare “tutti gli spider”) ma anche al livello di Disallow, anche insieme ad un secondo carattere accettato $.
Vediamo l’utilizzo di entrambi i caratteri.
Ipotizziamo di voler escludere tutti i file nel formato jpg dalla scansione dello spider.
Scriviamo:
User-Agent: *
Disallow: /*.jpg$
in questo modo indichiamo che tutti i file che terminano con .jpg devono essere esclusi dalla scansione dello spider.
Lo stesso potremo fare, ad esempio, per i file pdf.
User-Agent: *
Disallow: /*.pdf$
Potremmo invece permettere ad esempio l’accesso e la scansione di un file PDF specifico (ad esempio documento1.pdf)
Scriveremo:
User-Agent: *
Disallow: /*.pdf$
Allow: /documento1.pdf
Il carattere * può essere utilizzato anche in altre situazioni.
Ipotizziamo di voler impedire l’accesso degli spider a più cartelle con nomi simili. Ad esempio:
/immagini-mare
/immagini-montagna
/immagini-citta
Possiamo scrivere un’unica regola che impedisca l’accesso a tutte quelle cartelle o sottocartelle che iniziano con il nome “immagini”.
Scriveremo così:
User-Agent: *
Disallow: /immagini*/
Un altro utilizzo dell’asterisco * è quello di bloccare l’accesso a tutti gli URL che comprendono un determinato carattere.
Ad esempio il ? (punto interrogativo).
Scriveremo così:
User-Agent: *
Disallow: /*?
8F, HTACCESS
Il file htaccess (hypertext access) è un semplice file di testo che permette di raffinare, a livello di directory, le direttive per la configurazione di Apache HTTP Server: la piattaforma web server più diffusa al mondo.
In particolare per comprendere quali redirect è opportuno realizzare mediante il file .htaccess uno strumento FONDAMENTALE, da configurare per i nostri siti web, è la Google Search Console. L’ex tool per webmaster di Google ci mostrerà, nella sezione dedicata agli Errori causati da URL (dopo aver fatto accesso a GSC e aver selezionato la proprietà da analizzare dal menù laterale Scansione >> Errori di scansione) tutte le pagine che il motore di ricerca si aspetta di trovare e che al contrario emettono un codice di risposta erroneo, come ad esempio il 404 contenuto non trovato, e su cui è opportuno effettuare dei redirect a contenuti esistenti, ottimizzando così la SEO del prodotto su cui stiamo lavorando.
Modificare l’.htaccess è un’azione molto delicata e che va effettuata solo dopo diverse prove su prodotti di test!
Alcune tecniche SEO grazie al file .htaccess
 Vediamo nel dettaglio cosa possiamo fare per migliorare il posizionamento delle nostre pagine sui motori di ricerca, applicando alcuni concetti SEO di base al nostro sito, mediante il file .htaccess.
Vediamo nel dettaglio cosa possiamo fare per migliorare il posizionamento delle nostre pagine sui motori di ricerca, applicando alcuni concetti SEO di base al nostro sito, mediante il file .htaccess.
Riscrittura degli URL
Realizzare degli URL semplificati agli occhi dell’utenza è un’ottima tecnica di base al fine di ottimizzare la SEO on-page di un sito web. Per questo motivo è necessario realizzare dei permalink di facile comprensione, che non abbiano caratteri speciali al loro interno (a parte i caratteri - o _), senza l’estensione del file e possibilmente brevi e incisivi.
Vediamo due veloci esempi di questa applicazione, entrambi per funzionare richiedono che il nostro server Apache abbia attivato il supporto per il mod_rewrite.
Riscrittura dell’URL con elisione dell’estensione
Se le pagine del nostro sito hanno un indirizzo del tipo http://www.sitoesempio.tlp/pagina-esempio.html possiamo riscrivere l’URL in chiave SEO http://www.sitoesempio.tlp/pagina-esempio.
Il codice da inserire nell’.htaccess sarà il seguente:
RewriteEngine on
RewriteRule ^(.*)$ $1.html
ALCUNI ESEMPI DI REDIRECT
1) Reindirizzamento da WWW a senza WWW:
RewriteEngine OnRewriteBase /RewriteCond %{HTTP_HOST} ^www.(.*)$ [NC]RewriteRule ^(.*)$ http://%1/$1 [R=301,L] |
2) Redirect da senza WWW a WWW:
RewriteEngine OnRewriteCond %{HTTP_HOST} !^www.RewriteRule ^(.*)$ http://www.%{HTTP_HOST}/$1 [R=301,L] |
(altro codice stesso risulato)
RewriteEngine OnRewriteCond %{HTTP_HOST} ^tuodominio.it [NC]RewriteRule ^(.*)$ http://www.tuodominio.it/$1 [L,R=301] |
3) Redirect da vecchio dominio a nuovo dominio
RewriteEngine OnRewriteCond %{HTTP_HOST} !^www.vecchiodominio.com$RewriteRule (.*) http://www.nuovodominio.com/$1 [R=301,L]RewriteCond %{HTTP_HOST} !^vecchiodominio.com$RewriteRule (.*) http://www.nuovodominio.com/$1 [R=301,L] |
(altro codice stesso risulato)
RewriteCond %{HTTP_HOST} ^(www.)?vecchio-dominio.com [NC] RewriteRule (.*) http://nuovo-dominio.com/$1 [R=301,L] |
4) Redirect da vecchio sotto dominio a nuovo sotto dominio
RewriteEngine OnRewriteBase /RewriteCond %{HTTP_HOST} ^sottodominio.vecchio.com$RewriteRule ^(.*)$ http://sottodominio.nuovodominio.com/$1 [R=301,L]RewriteCond %{HTTP_HOST} ^www.sottodominio.vecchiodominio.com$RewriteRule ^(.*)$ http://sottodominio.nuovodominio.com/$1 [R=301,L] |
5) Redirect da vecchio dominio a nuovo sotto dominio
RewriteEngine onRewriteRule ^(.*)$ http://www.your-new-domain.com/$1 [R=301,L] |
OPPURE PROVARE:
Options +FollowSymLinksRewriteEngine onRewriteRule (.*)$ http://www.nuovosito.com/$1 [R=301,L] |
6) Redirect da vecchia cartella verso nuova cartella:
RewriteRule ^vecchiacartella/(.*)$ /nuovacartella/$1 [R=301,NC,L] |
7) Redirect da cartella a nuovo dominio ma stessa cartella:
Redirect 301 /cartella http://www.nuovodominio.com/stessacartella |
8) Redirect da cartella verso la cartella root principale:
RewriteRule ^cartella/(.*)$ /$1 [R=301,NC,L] |
Di seguito un esempio contenuto all’interno di un file htaccess che include il codice di default di wordpress e un redirect 301.
# BEGIN WordPressRewriteEngine OnRewriteBase /RewriteRule ^index.php$ - [L]RewriteCond %{REQUEST_FILENAME} !-fRewriteCond %{REQUEST_FILENAME} !-dRewriteRule . /index.php [L]# END WordPress#redirectredirect 301 /vecchio-link http://www.miosito.it/nuovo-link. |

